
Malware authors like to use string obfuscation to make their code harder to analyze and detect. One obfuscation technique is to insert special characters into a string, and then use some code to remove those special characters at runtime. This technique is simple but effective, as it can hide the actual string from being easily identified.
I recently came across an example of this technique on Twitter. So I thought, I will build my own version of this obfuscation and open-source it. For this, I revived an old project that followed the same concept but uses primarily homoglyphs. Homoglyphs are characters that look similar to alphabetical characters but are actually from a different alphabet.
While this technique is not as secure as encryption, it can still be useful for malware authors who want to avoid detection by simple string analysis and other static analysis techniques. Not encrypting or encoding the strings will also help avoid entropy-based detections.
As you might know, I have a minor obsession with fun names for my projects, so this time I came up with the name MurkyStrings, why? Well, we obscure strings by adding random characters which are just like fog, making the strings murky. Anyways let’s dive into the code :D
Abusing string replace
The main idea is to insert a few different homoglyphs into the original strings to confuse reverse engineers and obfuscate the true content of the string. The inserted characters will then be removed on runtime using a method from C#’s String class. Here is an example of the decompilation results:
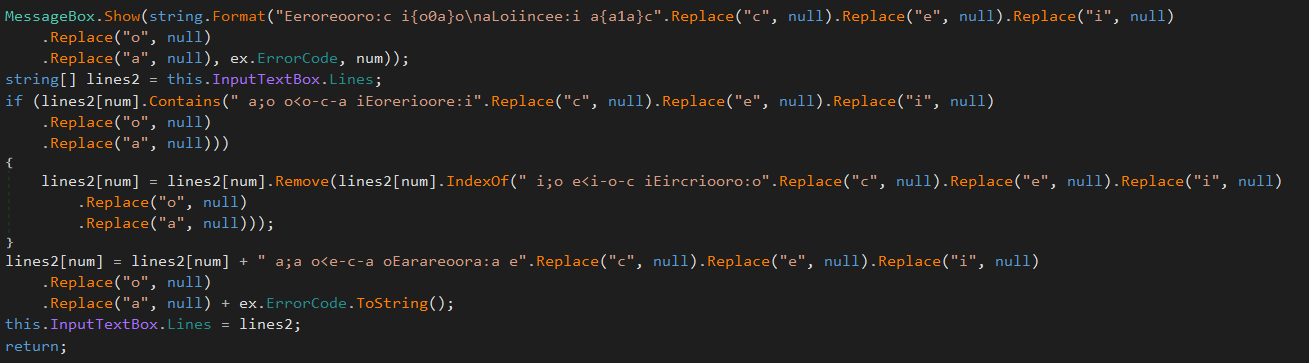
As you can see we are using a variety of homoglyphs that look exactly like the normal alphabetical characters. To make the whole thing a little more confusing to the human eye I did make sure that all homoglyphs I use are emitted right after or before the corresponding alphabetical character.
So a normal 'a' in the string will be followed or led by a Cyrillic 'а' and so on. Any other character will result in a random available homoglyph being emitted. See the following function for reference:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
private char GetHomoglyph(char input)
{
char[] glyphs = {'а', 'е', 'і', 'о', 'с'};
switch (input)
{
case 'a':
return glyphs[0];
case 'e':
return glyphs[1];
case 'i':
return glyphs[2];
case 'o':
return glyphs[3];
default:
return glyphs[_random.Next(glyphs.Length)];
}
}
To implement the above we parse all methods specifically their method body going through the instructions one by one and matching on Ldstr instructions. When we find a string assignment we take its operand as the target string and insert the homoglyphs as discussed before. After we inserted all the homoglyphs into the string, we need to add the code that will remove them on runtime. We insert an Ldstr isntruction that pushes the homoglyph we need to replace. Next, we insert an Ldnull instruction, which we do so the homoglyph is replaced with nothing. At last, we insert a Call instruction to System.String.Replace(System.String, System.String). We repeat this three-instruction pattern for all available homoglyphs, but instead of a Call, we emit a Callvirt instruction for all following replacements.
The result of this can be seen in the decompiled code shown earlier.
I have also included an option to use a simpler form of replace abuse. In this simpler mode, only one special character is used to obscure the strings, we insert a random amount of these special characters for each character of the target string. This way we need to call Replace only once, saving us a lot of allocations. Since strings are immutable in .NET any changes to an existing string will result in a new string being allocated.
Abusing string Remove
Another idea that follows this concept is inserting random text or names into strings and using the Remove method to remove them again at runtime. To achieve this I parse method names from the System namespace and insert multiple of them into the strings to be obfuscated. Afterward, we inject some CIL again. The injected CIL will remove the inserted text and consists of three instructions per insert. Two Ldc.I4 the first being the start index and the second being the length to be removed. During the obfuscation of the original string for every added text we saved the index at which it was inserted and the length of it. Thus we can simply injected it with the CIL. The last instruction is again a Call or Callvirt with System.String.Remove(System.Int32, System.Int32) as its operand. This method removes everything between the given starting index and the length from the string. The resulting decompilation will look somewhat like this:

The inserted names are parsed directly from the System namespace, concated together, and randomly inserted into the target string, with occasional spaces to further obfuscate the actual content. However there are a few issues with this method: For example, one of the randomly inserted method names might be a name that would be considered suspicious by an AV/EDR or analysis tool. Another problem is that the inserts might not overlap with an important part of the target string, revealing parts of the original content. To improve this, we could use a dictionary of known inconspicuous names, or generate random strings. Since the code is open source you are free to change the code to your liking/needs.
Stacking both techniques
Both of these techniques work great on their own but what if we combine them? Well, it gets pretty messy but works just fine. By applying the homoglyphs after the removal obfuscation we also eliminate the risk of any of the inserted method names being flagged. Additionally, these combined strings are much less humanly readable. Check the following screenshot for the decompilation results:
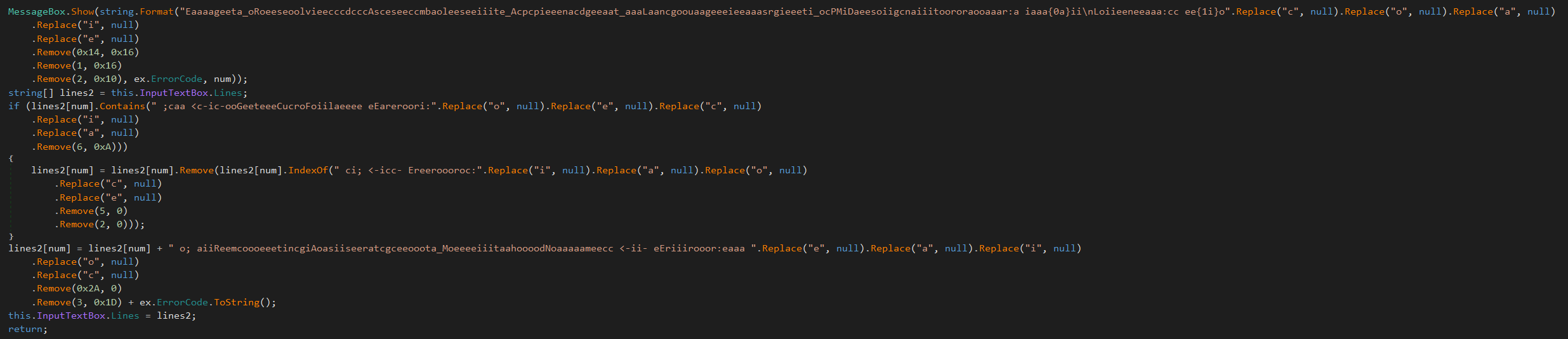
You should however keep in mind that this will result in quite a few allocations since we modify the string multiple times. For a simple loader etc. this will not have a meaningful performance impact therefore it can be neglected.
Closing words
I hope you enjoyed this post, and maybe have learned something or found a tool for future use.
Checkout the full source code of the project on GitHub