
Taking a detailed look at my .net executable packer Origami, specifically about the runtime and how it works. Also giving some general overview about packing executables. Basic knowledge of C# and the PE Format is recommended.
What is a packer?
A packer (specifically a runtime packer) is a software that unpacks itself or a payload in memory when executed. The original idea was to make files smaller due to storage and bandwith limitations, hence why this practice is also referred to as “executable compression”. But with the present-day broad availability of mass storage and increasing bandwith this is rarely needed. Which leads to the present day were packers are mostly used to make reverse engineering more difficult or in some cases hide malicious code from static scanning.
Due to the increasing malicious use of packers I decided to not include any major anti reverse engineering or stealth features. The write up will only focus on the basic concept of compressing an executable and unpacking it on runtime.
Writing your own packer
When I first looked into writing a packer I came accross the native packer UPX, which uses PE sections to store the packed executable data (payload). Since to my knowledge no open source .NET packers exist that tinker with PE sections. I set myself the goal to create the first open source .NET packer using PE sections. Most existing .NET packers rely on embedded resources or pre-initialized arrays for payload storage and I wanted do to something different. (When I recoded Origami, I added another payload storage option besides the PE section. You can choose between debug directory and PE section now)

For easier perception I tried to visualize my idea.
Processing the data and creating a stub
We begin by parsing our input executable as raw data (bytes). For further processing we will use AsmResolver. Additionally we parse the input executable as a ModuleDefinition which we will later use to obtain some basic info like FileCharacteristics, PEKind etc. these values will be used for the stub creation. Furthermore we need to parse the custom attributes from the input executable and import them into the stub module.
The next step is building the stub executable, the stub is the part of the packer that unpacks the actual packed executable in memory. To run the unpacked executable from memory I will use simple Reflection invoking. First we create a new ModuleDefinition and pass the following arguments: payloads module name, payloads CorLib assembly as AssemblyReference. Once we created the module for the stub we will apply the previously mentioned info and custom attributes from our payload module. Code reference can be found here
After that we will add the payload data to our stub (actually I inject the loader first but we will skip that for now, since the loader code requires a longer explanation). Before we add the payload data it will be compressed and encrypted with a single xor operation. For compression and decompression I use the .NET inbuilt DeflateStream.
If the PE section mode was chosen we add a new PESection containing a DataSegment which holds our payload. The new PESection will be called .origami. The Characteristics need to include atleast the read access flag, I additonally apply the unintialized data flag.
If the debug directory mode was chosen we clear the current debug directory and add a new CustomDebugDataSegment containing a DataSegment storing our payload instead of actual debug information. I will not go into detail explaining the code for this process as I think its fairly easy to understand, however the code references are included below if youre interested.
Code reference for the PE section packer can be found here
Code reference for the debug directory packer can be found here
Now to the step we skipped, injecting the loader code. The loader is the part that will unpack the payload at runtime.
The PE section loader
This loader code will be used together with the additional PE section mentioned in the previous paragraph. It parses the PE header on runtime to find the additional section, extract the data from it and then use it to invoke the original executable.
1
2
3
4
5
6
7
8
9
10
// Call GetHINSTANCE() to obtain a handle to our module
byte* basePtr = (byte*) Marshal.GetHINSTANCE(Assembly.GetCallingAssembly().ManifestModule
byte* ptr = basePtr;
// Parse PE header using the before obtained module handle
// Reading e_lfanew from the DOS header
ptr += *(ushort*) (ptr + 0x3C
// Reading NumberOfSections the file header
ushort NumberOfSections = *(ushort*) (ptr + 0x6
ushort optHeaderSize = *(ushort*) (ptr + 0x14
ptr += 0x18 + optHeaderSize;
Lets look at the Main method which will be injected into the stub and used as its EntryPoint. First we obtain a pointer to the base of our module (basePtr), aka the beginning of the PE header. After we assign ptr the value of basePtr. We then use the ptr variable to parse the relevant information for reading the sections from the PE header.
Then we get the value of e_lfanew a field defined in the DOS header which indicates the address of the new executable header. The field is located at offset 0x3C. The value of e_lfanew is by default 0x80 however it doesnt have to be since there are certain cases were additional data exists between DOS header and new executable header.
After we added the value of e_lfanew to ptr we will go on to read the field NumberOfSections from the new executable header we obtain that value by adding the offset 0x6 to ptr and casting the pointer to an unsigned short pointer, the cast is required because NumberOfSections is of type WORD which in C# equals a ushort. We then dereference the casted pointer to aquire the value of NumberOfSections from the PE header and assign the value to our local called NumberOfSections.
We repeat the above described but this time we add a different offset 0x14 to obtain the value of SizeOfOptionalHeader. This value is needed since the optional headers size changes depending on bitness. The 32bit optional header is slightly smaller than the 64bit optional header, which means following data differs in position depending on the size of the optional header. We assign the aquired value to optHeaderSize
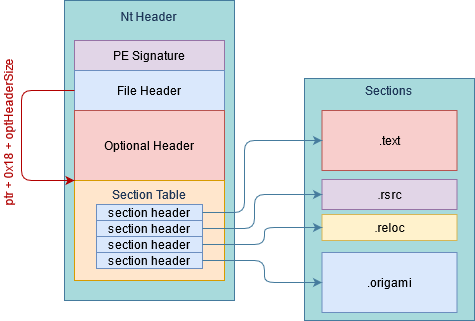
In the next step we add an offset 0x18 (size of file header) and the value of optHeaderSize to ptr basically we skip the file header and the optional header and jump to the beginning of the section table. Now we need to parse the single sections from the section table.
1
2
3
4
5
6
7
8
[StructLayout(LayoutKind.Explicit)]
private struct IMAGE_SECTION_HEADER
{
[FieldOffset(0)] public fixed byte Name[8];
[FieldOffset(12)] public uint VirtualAddress;
[FieldOffset(16)] public uint SizeOfRawData;
[FieldOffset(36)] private uint Characteristics;
}
This struct is used to parse the individual section headers from the section table. Each section header contains additional information about the section. However we only need a few fields from that header: Name, location in memory VirtualAddress and the size of the section SizeOfRawData. The last field Characteristics is not used but required to get the correct size of the struct. reference for the stuct defintion can be found here
1
2
3
4
5
6
7
8
9
// Read section headers
var ImageSectionHeaders = new IMAGE_SECTION_HEADER[NumberOfSections];
for (int headerNo = 0;
headerNo < ImageSectionHeaders.Length;
headerNo++)
{
ImageSectionHeaders[headerNo] = *(IMAGE_SECTION_HEADER*) ptr;
ptr += sizeof(IMAGE_SECTION_HEADER);
}
The loop parses all section headers and puts them in an array ImageSectionHeader. To read the section header we use the previously mentioned struct as a pointer. C# accepts structs as a pointer if it only contains unmanaged types, and that is the reason for the fixed byte in the struct since a C# byte array is not an unmanaged type.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// Get name of EntryPoint
string name = Assembly.GetCallingAssembly().EntryPoint.Nam
// Iterate through all PE sections
foreach (var section in ImageSectionHeaders)
{
// Check if PE section name matches first 8 bytes of stub EntryPoint
bool flag = true;
for (int h = 0; h < 8; h++)
if (name[h] != *(section.Name + h))
flag = fals
if (flag)
{
// Initialize buffer using size of raw data
// Copy data from PE section into buffer and simultaneously (un)xor it
byte[] buffer = new byte[section.SizeOfRawData];
basePtr += section.VirtualAddress;
fixed (byte* p = &buffer[0])
{
for (int i = 0; i < buffer.Length; i++)
{
*(p + i) = (byte) (*(basePtr + i) ^ name[i % name.Length]);
}
}
...
After parsing all the section headers we aqurire the calling assemblies managed EntryPoint name which will be .origami. The name is then stored as string name which will be later used for xor decryption and matching the correct section. We continue by finding the section that contains our payload. We iterate through our array of section headers and check if any sections name matches name. If we find a matching section we use it to get the payload. First we initialize a byte array buffer with the SizeOfRawData of our matched PE section. Then we add the VirtualAddress of the section to basePtr, its important that we use basePtr since the VirtualAddress is relative to the base of the module. Next step is copying the data from the PE section into our buffer, using a simple byte pointer operation. Simultaneously we apply the same xor operation as during the encryption to decrypt the payload byte by byte.
1
2
3
4
5
// Decompress data from the buffer
using var origin = new MemoryStream(buffer);
using var destination = new MemoryStream();
using var deflateStream = new DeflateStream(origin, CompressionMode.Decompress);
deflateStream.CopyTo(destination);
Once we are done copying and decrypting the data we pass the buffer into a MemoryStream (origin). The origin stream is then passed to a DeflateStream with the parameter CompressionMode.Decompress to decompress the payload. The decompressed data is then copied from the DeflateStream to a new MemoryStream here called destination.
Now in order to run the payload we need to invoke it. We pass the buffer of the destination stream, which is the streams content as a byte array, into an Assembly.Load() call. We can the locate the loaded assemblies EntryPoint and invoke it. Additionally if any commandline arguments were provided we pass them to the payload executable. Code reference can be found here
The debug directory loader
This loader is used together with a lesser known part of the PE structure, the debug directory. It is a special data directory used to store debug information for an executable. However since the data stored in this directory can be anything we can abuse it for our packers payload. The code is in theory very similar to the previously described PE section loader. What changed is the part of locating the compressed data.
1
2
3
4
5
6
7
8
9
10
11
// Call GetHINSTANCE() to obtain a handle to our module
byte* basePtr = (byte*) Marshal.GetHINSTANCE(Assembly.GetCallingAssembly().ManifestModule
// Parse PE header using the before obtained module handle
// Reading e_lfanew from the DOS header
byte* ptr = basePtr + *(uint*) (basePtr + 0x3C
// Check the optional header magic to determine 32-bit vs 64-bit
short optMagic = *(short*) (ptr + 0x18
// 0x20b = IMAGE_NT_OPTIONAL_HDR64_MAGIC
uint DebugVirtualAddress = optMagic != 0x20b
? *(uint*) (ptr + 0xA8)
: *(uint*) (ptr + 0xB8);
One again we begin by obtaining a pointer to the base of our module (basePtr), aka the beginning of the PE header. We then get the value of e_lfanew as described previously and assign its value plus basePtr to ptr. Next thing we aquire is the value of Magic, the first field of the optional header and assign it to optMagic. Depending on bitness the value of Magic is either 0x10b for 32bit or 0x20b for 64bit. Since the next value that we need is located in the optional header we need to determine which header is present (32bit header is smaller than 64bit header, which results in different offsets). Next we check if optMagic is not 0x20b, if that is the case we assign the value located at ptr plus offset 0xA8 to DebugVirtualAddress. The pointer chain points to the location of Debug Directory RVA in the 32bit optional header. If optMagic is 0x20b a different offset 0xB8 will be added to ptr which results in the value of Debug Directory RVA in the 64bit optional header getting assigned to DebugVirtualAddress.
1
2
3
4
basePtr += DebugVirtualAddress;
uint SizeOfData = *(uint*) (basePtr + 0x10);
uint AddressOfRawData = *(uint*) (basePtr + 0x14);
basePtr -= DebugVirtualAddress;
After finding the relative virtual address (RVA) of the debug directory (stored in DebugVirtualAddress) we add it to basePtr. After we parse the first entry of the debug directory which is our payload, since in the stub generation we cleared the debug directory and added only our entry containing the payload. We only need 2 fields from the entry SizeOfData and AddressOfRawData to obtain them we apply an offset of 0x10 to basePtr since we added DebugVirtualAddress to basePtr it now points to the beginning of the debug directory. And the value at offset 0x10 in the debug directory entry is SizeOfData. Next we do the same for AddressOfRawData using the offset 0x14. Once we have aquired these two values we subtract DebugVirtualAddress from basePtr to ensure its pointing to the beginning of the PE header again. That step is required since AddressOfRawData which is the location of our payload data, is relative to the base of the module.
1
2
3
4
5
6
7
8
9
byte[] buffer = new byte[SizeOfData];
basePtr += AddressOfRawData;
fixed (byte* rawData = &buffer[0])
{
for (int i = 0; i < buffer.Length; i++)
{
*(rawData + i) = (byte) (*(basePtr + i) ^ name[i % name.Length]);
}
}
This snippet is almost identical to the PE section loader except the location we copy the data from is aquired by adding AddressOfRawData to basePtr and we use SizeOfData to initialize our buffer byte array. The copying, decryption, decompression and invoking is done exactly the same way as in the PE section loader.
Finnishing the packed file
After all the above is done all thats left to do is writing our stub module to disk. Once the file is written to disk youve got your own packed version of the input file.